| Cím: | Önhasonlóság az Interneten | ||
| Szerző(k): | Fekete Attila | ||
| Füzet: | 2001/április, 236 - 243. oldal |  PDF | MathML PDF | MathML |
|
| Témakör(ök): | Szakmai cikkek | ||
|
A szöveg csak Firefox böngészőben jelenik meg helyesen. Használja a fenti PDF file-ra mutató link-et a letöltésre. 2000. júniusában az ERICSSON cég kutatási szervezete és az ELTE TTK együttműködési szerződést írt alá; közös kutatási program megvalósítására létrehozták a Kommunikációs Hálózatok Laboratóriumát. A programban a ,,komplex rendszerek'' kutatásával foglalkozó oktatók, PhD ösztöndíjasok és egyetemi hallgatók vesznek részt. Az alábbi cikk ‐ amely a tavalyi Téli Ifjúsági Ankéton tartott előadás kibővített változata ‐ ennek a kutatásnak egy érdekes ágáról számol be. Az Internet születését 1969-re, az amerikai ARPANET (Advanced Research Projects Agency NET) megalakítására szokták datálni. Az ARPANET egy számítógépes hálózatot jelentett, amelyet azért hoztak létre, hogy az ARPA programban résztvevő, egyre népesebb kutatócsapat meg tudjon osztozni a rendelkezésre álló, ám korlátozott számú számítógépen. Pár éven belül aztán a hálózatot megnyitották az egyetemek és a nagyközönség számára is, amivel megkezdődött a mai Internet rohamos terjeszkedése. A következőkben röviden bemutatunk egy telefonhálózatok leírására alkalmas modellt. Ezután vázlatosan ismertetjük az Internet adatforgalmát szabályozó egyik lefontosabb algoritmust, a TCP-t. Megadunk néhány mennyiséget, amelyek az adatforgalom statisztikus tulajdonságait jellemzik, és megmutatjuk, hogy miben térnek el ezek a tulajdonságok az Internetnél és a klasszikus telefonhálózatoknál. Végül ismertetünk egy elképzelést arról, hogy milyen mélyebb oka lehet az Internet klasszikustól eltérő viselkedésének. Képzeljünk el egy telefonközpontot, ahova a település lakójától egymástól függetlenül és véletlenszerűen futnak be a hívások. Tegyük fel, hogy a telefonközpont hívást tud fogadni egyszerre, és ha minden vonal foglalt, akkor a telefonálónak várakoznia kell. Feltesszük, hogy a várakozók egy sorban állnak, ugyanúgy, mint például a nézők a mozipénztáraknál1. Osszuk fel az időt nagyon rövid intervallumokra. Tegyük fel, hogy a időintervallum alatt valószínűséggel kezdeményez valaki új hívást, függetlenül attól, hogy mikor telefonált utoljára, és valószínűséggel teszi le valaki a kagylót, függetlenül attól, hogy mióta telefonált. A telefontársaság részéről egy lehetséges kérdés az, hogy hány hívás fogadására alkalmas központot telepítsen az adott városba. Kézenfekvő válasz lenne, hogy -et, ez azonban igen gazdaságtalan volna, mivel nagyon kicsi annak a valószínűsége, hogy egyszerre mind az lakó telefonálni akar. Pontosítva tehát a kérdést: hány hívás fogadására legyen alkalmas a központ, ha azt akarjuk, hogy valószínűsége legyen csak2, hogy valakinek várakoznia kell, mert nem kap vonalat egy adott időintervallumban. Egy nagyon hasonló problémát már 1917-ben megoldott A. K. Erlang (1878‐1929) dán matematikus. A megoldást Erlang-formulának nevezik a távközlésben. (A mozipénztáraknál nem nevezik Erlang-formulának a megoldást, pedig ugyanez érvényes ott is.) A feladatot a következőképpen lehet megoldani. Jellemezzük a rendszert azzal az természetes számmal, amely megadja, hogy hányan akarnak éppen telefonálni egy adott időintervallumban. Ha lakó akar telefonálni, akkor azt mondjuk, hogy a rendszer az -edik állapotban van. Feltettük, hogy igen kicsi, ezért csak a következő három eseménynek van számottevő valószínűsége (2. ábra):
Jelöljük -nel annak a valószínűségét, hogy a rendszer hosszú idő elteltével az -edik állapotban tartózkodik. Megmutatható, hogy ez a rendszer olyan, hogy a kezdőfeltételtől3 függetlenül hosszú idő múlva egy meghatározott értéket vesz fel. Az is belátható, hogy teljesül a következő egyenlet:
Egészen 1989-ig azt gondolták, hogy az említett Erlang-formula alkalmazható az Internet esetében is. 1989 augusztusában azonban a Bellcore helyi Ethernet hálózatán olyan mérési eredményeket kaptak, amelyek ellentmondtak a klasszikus modellek jóslatainak. Ennek bemutatása előtt tekintsük át, hogyan lehet egy számítógépes hálózat működését elképzelni. Egy TCP nevű program a továbbítandó adatokat először kis csomagokra bontja, amelyek fejlécébe (mint egy postai levelezőlapra) beírja a küldő és a feladó címét, a feladás időpontját, és még néhány további adatot, majd sorban elküldi a csomagokat. Ha egy csomag sikeresen megérkezett, akkor a címzett visszaküld egy nyugtát a csomagról. Ha a TCP egy adott idő múlva még mindig nem kapott nyugtát egy csomagról, akkor azt a csomagot ismét elküldi. Az Interneten levő csomagok központokon (routereken) keresztül haladnak a címzett számítógép felé. A router a beérkező csomagokat egymás után, egyesével továbbítja a megfelelő irányba. Ha egyszerre több csomag érkezik, akkor a csomagoknak az érkezés sorrendjében sorba kell állniuk. A router tárolókapacitása azonban véges, és így amelyik csomag már nem fér be a sorba, azt kénytelen eldobni. Ez a csomagvesztés jelzi a TCP számára, hogy túllépte a rendelkezésre álló kapacitást (sávszélességet). Optimálisan akkor működik a TCP, ha éppen a rendelkezésre álló sávszélességet használja fel. A TCP által a hálózatból lefoglalt kapacitást a kiküldött adatmennyiség, valamint a küldés és az érkezés időkülönbségének hányadosa adja meg. Az optimális sávszélesség azonban minden pillanatban változhat, hiszen nem tudni, hogy egy adott időpillanatban hány másik TCP próbálja meg ugyanazt a vonalat használni. A TCP ezért dinamikusan megpróbálja meghatározni a rá jutó kapacitást. Számos TCP verzió létezik, és ezek főként az optimalizációs algoritmusban térnek el egymástól. A TCP Reno verziója például ‐ erősen leegyszerűsítve ‐ először exponenciálisan növeli a hálózatba kiküldött csomagok számát, majd az első csomagvesztés után megfelezi a csomagküldés sebességét; ezután már csak lineárisan növeli a sebességet, majd csomagvesztés után ismét felez (3. ábra). A klasszikus telefonhálózat és az Internet működését összehasonlítva látható, hogy míg a telefonhálózat esetén minden telefonáló csak egy előre meghatározott sávszélességet használ, addig a számítógépes hálózatokban a TCP a maximális rendelkezésére álló kapacitást megpróbálja kihasználni. A másik jelentős különbség a két hálózat között, hogy míg egy telefonvonal az egész beszélgetés alatt biztosított a két fél között, addig két számítógép között az adatok kis csomagokban, szakaszosan érkeznek. Az említett különbségekből még nem feltétlenül következne, hogy a két rendszert nem lehet ugyanazzal a modellel leírni. A mozipénztár előtti sor és a telefonhálózatban kialakuló sor is különbözik, mégis nagyon jól leírja mindkettőt az Erlang-formula. Lássuk tehát, hogy hogyan lehet mennyiségileg vizsgálni a két hálózat közötti különbséget. Legyen egy véletlen sorozat, például legyen a telefonálók, vagy az Internetben levő csomagok száma az -edik időintervallumban. Definiáljuk a következő, úgynevezett korrelációs függvényt:
A ,,klasszikus'' telefonhálózatok modellezése során azt tapasztalták, hogy a korrelációs függvény nagyon nagy -ra exponenciálisan csökken, azaz
A korrelációs függvény viselkedéséből egy másik fontos tulajdonságot is levezethetünk. Osszuk az sorozatot méretű, nem átfedő blokkokba, és tekintsük azt az új sorozatot, ami ezeknek az új blokkoknak az átlagából áll:
A korrelációs függvény mellett vezessünk be egy másik mennyiséget is, ami azt mutatja meg, hogy az mennyiség mennyire ingadozik az átlagértéke körül:
-et az eredeti véletlen sorozat korrelációs függvényével:
Az eddigiekből sejthető, hogy a rendszert igazából egyetlen paraméter, a kitevő jellemzi. Az ezen alapuló modellek is hamar megszülettek. Az alapötlet az időegység újraválasztásán alapul, amit például úgy lehet elvégezni, mint azt az előző fejezetben bemutattuk. A természetben, a mindennapi életben máshol is gyakran előfordulnak olyan objektumok, amelyek különböző mérettartományokban ‐ bizonyos értelemben ‐ hasonlítanak egymásra. Ezeket az objektumokat általában fraktáloknak szokták nevezni. Véletlen folyamatok, mint például az Internet forgalom esetében, kissé bonyolultabb a helyzet, ugyanis maga az sorozat ‐ véletlen folyamatról lévén szó ‐ nem lehet önhasonló, statisztikus tulajdonságai ‐ mint például a korrelációs függvénye ‐ azonban már lehet az. Belátható például, hogy a blokkosítással kapott sorozat korrelációs függvénye szintén szerint változik. Az önhasonlóságot sokféleképpen lehet definiálni. Az egyik lehetséges definíció például, hogy önhasonló, ha minden -re
Az Internet vázlatosan ismertetett modelljében azt tapasztaljuk, hogy különböző mennyiségek hatványfüggvény szerint változnak. A modellt tanulmányozók egyik fontos célkitűzése az, hogy kapcsolatot találjanak az egyes hatványfüggvények kitevői között, és meghatározzák a független paraméterek számát. Belátható például, hogy , azaz a két paraméter nem független egymástól. Arra vonatkozóan, hogy mi okozza a fent bemutatott önhasonlóságot többféle magyarázat született. Az egyik legelfogadottabb elmélet szerint a számítógépen található fájlok méretében, illetve a felhasználók viselkedésében kell keresni az okot. Legyen annak a valószínűsége, hogy egy szamítógépen egy véletlenszerűen kiválasztott fájl mérete az intervallumba esik. Az függvényt eloszlásfüggványnek hívják. Mérések azt mutatják, hogy , azaz a fájlméretek eloszlása szintén hatványfüggvény szerint csökken. A fentiek analógiájára definiálhatjuk azt az eloszlásfüggvényt, ami megadja, hogy a felhasználó (a program, az alkalmazás) milyen valószínűséggel várakozik ideig. A mérések szerint ez is hatványszerű viselkedést követ. Mindez egy tételen keresztül kapcsolódik az önhasonlóság forgalmához. A tétel úgynevezett ON/OFF folyamatokról szól. Az ON/OFF folyamat olyan forgalmat jelent, amikor a forgalmat generáló forrásnak mindössze két állapota lehetséges: bekapcsolt (ON) vagy kikapcsolt (OFF). A bekapcsolt és kikapcsolt állapotok váltakozva követik egymást, és az egyes állapotokban véletlenszerű ideig tartózkodik a rendszer. A tétel szerint, ha olyan ON/OFF folyamatokat összegzünk (4. ábra), amelyekben az ON vagy az OFF állapotban tartózkodás valószínűségeloszlása hatványszerű viselkedést mutat, akkor az eredő forgalom önhasonló lesz. Az Internet forgalmát tehát e szerint a modell szerint sok-sok párhuzamos, egymástól független ON/OFF folyamat összegeként lehet elképzelni, ahol az ON vagy az OFF folyamat eloszlása hatványfüggvényt követ. A kutatók többségének véleménye szerint ezek az ON állapotok az Internet felhasználói által indított fájl-letöltéseknek feleltethetők meg, az OFF állapotok pedig az ezek közötti szüneteknek. Hozzá kell tennünk, hogy nemrégiben olyan eredmények is születtek, amelyek azt mutatják, hogy a TCP önmagában, hatványszerű fájl-eloszlás nélkül is képes önhasonló forgalmat generálni.
Fekete Attila és Kommunikációs Hálózatok Laboratóriuma e-mail: fekete@ector.elte.hu 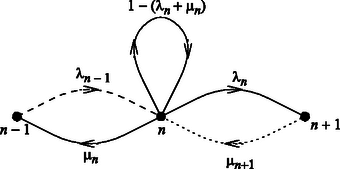 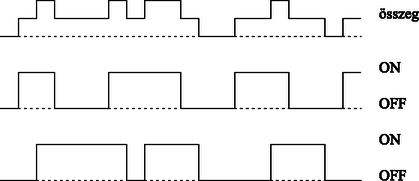  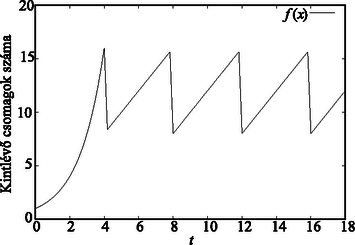 1Feltesszük, hogy a mozipénztárnál senki sem tolakszik előre, azaz aki előbb érkezett, az előbb is kerül sorra.2 valamilyen előre (mondjuk a szerződésben) meghatározott nagyon kicsi szám.3Akárhányan is telefonáltak a kezdőpillanatban. |