| Cím: | Mit lehet nyerni, ha egy kicsit engedünk a biztosból? 2. rész | ||
| Szerző(k): | Vancsó Ödön | ||
| Füzet: | 1994/április, 171 - 182. oldal |  PDF | MathML PDF | MathML |
|
| Témakör(ök): | Szakmai cikkek | ||
|
A szöveg csak Firefox böngészőben jelenik meg helyesen. Használja a fenti PDF file-ra mutató link-et a letöltésre. Az 1993/3. szám 104 ‐ 109. oldalán megjelent három probléma közül az első vizsgálata során jutottunk el az ún. Gauss-féle haranggörbéhez. Mivel ennek szerepe, mint a későbbiekben látni fogjuk, nemcsak a binomiális eloszlás közelítésekor jelentős, ezért szeretnénk megadni függvényként. illetve a komplex számokat ismerők számára nevezetes Moivre-féle képlet is. A sors játéka, hogy ez a faktoriálisokra vonatkozó képlet, amelyet néhány évvel később James Stirling is megadott, nem Moivre, hanem Stirling-formula néven vált ismertté: , ahol két ,,csúnya'' szám is szerepel: az és a . Az utóbbit nyilván minden olvasó ismeri, az előbbit csak az analízisben járatosabbak, akik már sorozatok határértékvel foglalkoztak. Az szám leggyakoribb definíciója: Ha tudjuk, hogy a egy primitív függvénye , akkor már majdnem megvan a keresett formula, hiszen az tényező ebből adódik. A hiba becslése adja a másik tényezőt. Megjegyezzük, hogy már esetén is kisebb a hiba, mint ( 10-nél 0,83%, 67-nél 0,12%), így nagy -ekre jól lehet használni a becslést. A továbbiakban ezt a formulát fogjuk használni az helyett: Ekkor 4. ábra Hogyan lehet ezzel most ténylegesen közelítő számításokat végezni? Számunkra általában binomiális összegek kellenek, pl. Az analízisből ismeretes azonban, hogy a fenti integrál csak közelítéssel számolható ki, nincs analitikus képlettel felírható primitív függvénye az függvénynek. Mivel nagyon gyakran használjuk ezt az integrált, van egy elfogadott jelölés: . A függvény értékeit táblázatban szokták megadni. Mivel szimmetrikus az origóra, ezért . Ebből a szimmetriából következik az is, hogy . Ezzel lehet negatív érékekre is meghatározni -t. (Lásd a 4. ábrát, és az 1. táblázatot. Mivel a binomiális eloszlás lépcsős függvény, míg a normális eloszlás folytonos, jobb illeszkedést kapunk az ún. korrekciós formulával (lásd az 5. ábrát is): 5. ábra Ezek szerint lehet számolni a binomiális eloszlás közelítésével. Van még egy fontos kérdés, hogy milyen nagy -re jó ez a közelítés. A helyzet bonyolult, mert ez -től is függ. Van egy még Laplace-tól származó gyakorlati kritérium, miszerint, ha Gyakorlásul nézzük meg, mi van, ha 10%-kal több megrendelést veszünk fel, hogy tele legyen a repülőgép. A 10% esetünkben 25 fő. Vajon mit lehet mondani, ha 275 megrendelést veszek föl, akkor milyen eséllyel fér be minden utazni szándékozó a gépbe? Esetünkben a várható érték míg a szórás Tehát , azaz kb.72% az esélye, hogy 275 megrendelést felvéve még nem kerülünk kellemetlen helyzetbe. Ezután próbáljuk meg az eredeti kérdést megválaszolni, tehát nem a megrendelésszám ismert, hanem annak az esélyét kérdezzük, vajon nem lép-e fel a visszamondás egy bizonyos rögzített esélynél kisebb valószínűséggel. Már egy kicsit tájékozottabbak vagyunk, hiszen pl. 99%-ra rögzítjük az esélyt, akkor tudjuk, hogy 252 megrendelés még bőven jó, s a 275 meg már túl sok. Természetesen végigpróbálhatnánk a kettő között minden számot, s kiderülne, hol lépjük át 0,99-es küszöböt. Azonban éppen azért csináltuk végig a fenti közelítő számolást, hogy annak hasznát vegyük. Tehát a kérdésünk a következőképpen szól: Legfeljebb milyen nagy -ekre lehet 0,99 eséllyel 250-nél kisebb vagy egyenlő az utazók száma? Ha most az utazók számát normális eloszlással közelítjük, amelynek várható értéke , szórása , akkor ehhez az kell, hogy az új változó kisebb legyen, mint legalább 99% eséllyel. Mivel az új változó standard normális eloszlású, azért látható az 1. táblázatból, hogy 2,33-nál már több, mint 99% eséllyel lesz kisebb a véletlen számunk, amely az utazók számát jelöli az jelentkező közül. Tehát , vagyis . Mivel a bal oldal pozitív, azért is az kell legyen, tehát . Négyzetre emlve: Ezzel választ adtunk a kérdésre, ha a biztonsági szint 99%-os, akkor legfeljebb 265 megrendelést vehetünk föl. Ezzel a várható utasszám -ről -re emelkedett. Ez bevétel növekedést jelent járatonként! S a ,,túlcsordulási'' rizikó csak 1%. Természetesen kiszámolható más rizikó faktorral is a feladat, ezt gyakorlásul ajánjuk az olvasónak. Ha 5%-os a rizikó faktor, akkor hány megrendelés vehető föl, s mi a helyzet 0,1% esetén? Mekkora átlagos bevétel növekedést jelentenek járatonként a fenti esetek? Látható, hogy a rizikó faktor és a bevétel növekedés egyirányú, ha csökkentem a rizikót, csökken a bevétel is. Ebben már a managementnek kell döntenie. Nyilván a visszamondás egy esetleges hosszú távú utast taszít át a konkurenciához, s így nem szabad gyakorinak lennie. Végezetül ne felejtsük el, hogy a függetlenség fontos feltétel volt. Ha az egyes utasok nem függetlenek, akkor kell információ arról, hogyan függnek össze. Ha valaki csoportosan utazik pl. családdal, munkatársakkal, akkor gyakran a kiesése az egész csoport kiesését vonja maga után. Ekkor még többen esnek ki, vagyis az esélyeink a visszamondásnál nőnek, tehát becslésünk még inkább igaz lesz. Ha emiatt még több megrendelést akarunk felvenni, akkor ennek kalkulálásához további információ kell az együttes visszamondások számáról, gyakoriságáról. Ez egy lehetséges útja modellünk finomabbá tételének. Tudni kell azonban, hogy minden ilyen lépés, bár az eredmények egyre közelebb lesznek a valósághoz, növeli a matematikai nehézségeinket, amelyeket manapság leginkább a számítógépek segítségével lehet megoldani. Szimulációs és egyéb programokkal, vagy egyszerűen csak a sokmillió számítás elvégeztetésével. Nekünk azonban most csak az ismerkedés volt a célunk. A második probléma tisztázásáhz idézzük fel, miről van szó: 2. Probléma: (ismerve a sokaság eloszlását, mit lehet mondani egy minta eloszlásáról, amelyet ebből a sokaságból vesznek?) Egy, az Országos Rendőrfőkapitányság és a Főügyészség által közölt statisztikából tudjuk, hogy Magyarországon 1990-ben 341 061 bűncselekmény vált ismertté (feljelentés, eljárás indítás), s ebből 187 655 esetben az elkövető ismeretlen maradt. Ha most kiválasztunk 1000 bűncselekményt a 341 061-ből, akkor vajon mekkora eséllyel lesz legalább 400 esetben ismeretlen az elkövető? Mit kell érteni kiválasztáson? Hogyan lehet megvalósítani a kiválasztás ,,véletlenszerűségét'', amelyre a modellünk mond valamit? Nagyon gyakori, hogy egy nagy sokaságról tudunk valamit, s arra vagyunk kíváncsiak, vajon hogyan tükröződik ez egy valahogyan kiválasztott jóval kisebb elemszámú mintában. Az alapvető kérdés persze éppen az lesz, hogy hogyan válasszuk ki ezt a mintahalmazt a teljes sokaságból, mint alaphalmazból. Azok a számítások, amelyeket majd elvégzünk, alapvetően arra támaszkodnak, hogy a mintahalmazt valamilyen módon ,,egyenletesen véletlenszerűen'' tudjuk kiválasztani, amin természetesen azt értjük, hogy semelyik elemnek sincs ,,prioritása'' a kiválasztási folyamat során. Ezt persze könnyebb kijelenti, mint megvalósítani. A legegyszerűbb eset, s természetesen egy bevezető példában ezt választottuk, amikor egyetlen egy tulajdonság fennállása szerint csoportosítjuk a sokaság elemeit. Vagyis az alaphalmaz elemei két osztályba sorolhatók, s az lesz a kérdés, hogy egy véletlenszerűen választott mintában milyen gyakorisággal várható a kétféle elem felbukkanása. Konkrétan a mi feladatunkban a felfedett, illetve a ki nem derített bűntények szerint osztályozzuk a bejelentett bűneseteket. Tudjuk, hogy a 341 061 esetből több mint a fele, 187 655 kiderítetlen maradt. Ez 0,55, vagyis az összes esetnek 55%-a. Vajon az 1000 ,,véletlenszerűen'' választott eset között hány felderítetlent találunk? Nyilván, ha biztosat akarunk mondani, akkor ez a szám 0 és 1000 között lesz. Vajon, ha egy kis rizikót vállalunk, akkor mennyire csökkenthető ez az intervallum? Mennyire igaz az, amit sokszor gondolunk, hogy ,,körülbelül'' 55% lesz a mintában is a kiderítetlen esetek száma? Mit jelent itt a ,,körülbelül'' szó, lehet-e valamilyen kvantitatív értelmet adni neki? Mennyire valószínű, hogy például legalább 400 felderítetlen eset lesz? Látható, hogy a kérdés nagyon hasonló az első problémához. Legalábbis ami a gondolkodásmódot illeti. A számolás sem lesz sokkal nehezebb, de itt is kell majd közelítést használni. Kíséreljük meg modellezni a problémát. Egyszerű kombinatorikai kérdésről van szó: 341 061 esetből kell kiválasztani 1000 esetet, ami a teljes véletlenszerűség feltételezése mellett -féleképpen tehető meg. Annak az esélye pedig, hogy éppen felderítetlen eset lesz ezek között, a klasszikus Laplace-féle formulával számolva (kedvező esetek száma osztva az összes esetek számával): . Feladatunkra a válasz: Ez a következőképpen interpretálható: van elem (az alapsokaság elemszáma), amelyből valamilyen megadott tulajdonságú, míg természetesen azon elemek száma, amelyeknek nincs meg az adott tulajdonsága. Eztuán kiválasztunk véletlenszerűen elemet (ez a minta), s azt kérdezzük, mekkora annak az esélye, hogy éppen darab lesz () a közül a mintában, feltéve, hogy . Ha jelöli a tulajdonsággal rendelkezők számát a mintában, akkor éppen az (1) alatti eloszlást kapjuk. A levezetésben valójában egy urnamodellt használunk, csak most eltérően az első problémától, visszatevés nélkül húzunk. Ha figyelembe vesszük, hogy az urna elemszáma jóval nagyobb, mint a húzások száma, akkor lényegében nem játszik jelentős szerepet a ,,vissza nem tétel''. Ezt felismerve várhatóan jó közelítés lesz a binomiális eloszlás, ahol tehát visszatesszük a húzás után a kihúzott elemet. Ennek pontos matematikai elemzésére még visszatérünk. Azaz: Átlagosan 550 körül lesz a fel nem fedett bűnesetek száma az ezerből, s hogy mekkora intervallumba kell esnie, az a rizikófaktortól függ. Esetünkben nem az intervallum, hanem a rizikófaktor a kérdés. A standard normális eloszlással becsülve adódik: A binomiális eloszlás normálissal történő közelítéséről már volt szó. A hipergeometrikus eloszlás kapcsolata a binomiális eloszlással jóval könnyebben áttekinthető, ezért itt bemutatjuk. Akik kevésbé érdeklődnek a matematikai levezetések iránt ‐ bár sokszor éppen abból lehet megérteni a dolog lényegét ‐ azok most tovább lapozhatnak a 2. táblázatig. Az alábbi közelítést szeretnénk megvizsgálni: A valóságban azonban és nem végtelen nagy, ezért jó lenne megvizsgálni, mekkora hibát követünk el ezzel a becsléssel. Ez nyilván függ valamint és viszonyától. Nyilván az utolsó tényezők, azaz és térnek el legjobban és -től. A hibának tehát jó felső becslése a szorzat. Ennél biztos kevesebbet hibázunk. Ennek értéke: , amit ismét felülről becsülhetünk. Ezúttal az első tényezőben helyett a legnagyobb lehetséges értéket, -et írva, és a -et elhagyva, valamint a második tényezőben a legkisebb -t, 0-t írva és ismét elhagyva a -et, adódik, hogy a hiba univerzálisan bármelyik tagot nézve, azaz tetszőleges k esetén biztos kisebb, mint . Ez egy nagyon durva felső becslés, de még ez is mutatja, hogy nem követünk el nagy hibát, még viszonylag nagy húzás százalék mellett sem. Esetünkben , míg , a hiba kisebb, mint , ami , azaz elenyésző, ennél a normális eloszlással történő közelítés jóval nagyobb hibát produkál. Összefoglalva tehát levezetésünket, megállapítható, hogy ha az elemszám legalább egy nagyságrenddel nagyobb a húzásszámnál, akkor semelyik tag közelítésében nem követünk el -nél nagyobb hibát, ami legalább öt húzás esetében az eredményt legfeljebb a hatodik tizedesjegyben változtatja meg. Valójában még ennél is kisebb a hiba, nem beszélve arról, ha a húzásszámnál több nagyságrenddel nagyobb az elemek száma. Természetesen, ha ez nem áll fenn, akkor nagy különbségek is felléphetnek, s a közelítés abszolút rossz, lásd például az alábbi esetet: Legyen egy urnában 20 golyó, 12 piros 8 fehér. 10-szer húzunk visszatevés nélkül. Vajon mekkora eséllyel lesz piros a húzott golyók között? Már tudjuk, hogy ezt hogyan számoljuk: az esély= . A megfelelő közelítés ebben az esetben az a binomális eloszlás lenne, amelynek paraméterei: , azaz annak az esélye, hogy éppen piros lesz a 10 húzás során: . 2. táblázat. Visszatevés nélküli húzás A hipergeometrikus eloszlás számolásakor figyelembe kell venni, hogy ha , akkor a számláló 0 lesz, hiszen nem lehet 8 elemből 9 elemet kiválasztani. Abban érdemes megállapodni, hogy , ha . Összehasonlításképpen a binomiális eloszlás megfelelő értékeivel: A második problémára adott válaszunk tehát az, hogy nagyon nagy (>0,9999999) eséllyel lesz több, mint 400 a fel nem fedett bűesetek száma, amely várhatóan 550 körüli lesz az 1000 esetből, s hogy mekkora intervallumba esik nagy eséllyel (tehát kicsi a rizikója annak, hogy ezen kívül essen) azt ki lehet számítani, ha előre adott, mit akarunk nagy esélyűnek nevezni. Itt is igaz, hogy jelentősen megrövidül az eredeti (0-1000) intervallum, ha egy igen pici rizikót merünk vállalni. Egyvalamivel még adósak vagyunk, nem mondtuk meg, hogy hogyan lehet véletlenszerűen választani, ami az egész gondolatmenet alapja volt. Gondoljuk meg, ha ez nem teljesül, akkor akár úgy is választhatok, hogy a fel nem fedett bűnesetek közül veszem mind az 1000 esetet, s így biztos, hogy 100% lesz a fel nem derítettek száma. Egy, a lottónál szokásos lehetőség, az urnából húzás lenne. Ez azonban aligha valósítható meg 341 061 golyóval, közben az egyenletességet folyamatosan keveréssel biztosítva. Jobb lehetőség kínálkozik a számítógépek felhasználásával, amit TV-s játékokból ismerhetünk. Az eljárás a következő: Sorbarendezzük valahogy az összes esetet, az embereket pl. a személyi számuk szerint, majd elkezdjük a gépen a listát ,,futtatni'', s valamikor tetszés szerinti pillanatban a listát megállítani. Ahol éppen tart a futás, az lesz az első elem. Ezután ezt töröljük, s az egész eljárás kezdődik elölről. (Ha nem töröljük az elemet, akkor a visszatevéses eljárás is szimulálható így számítógép segítségével.) Természetesen itt a megállítás véletlenszerűségére tevődött át a probléma. Ennek biztosítása sem egyszerű. Kis esetszám esetén persze lehet valami ,,igazi véletlen szerint'' megállítani, de mivel a futás hihetetlenül gyors az emberi reakcióidőhöz képest, kis esetszám esetén elég valamikor lenyomni a ,,megállító'' billentyűt, az teljesen véletlenszerű lesz. Nagy esetszámnál lehet, hogy valamiiyen ritmusra állunk be, s ez már esetleg determinisztikussá teszi az eljárást. Jó lenne persze teljesen automatizálni a dolgot, ez is megtehető (legalábbis valamilyen pszeudo-véletlen szinten), de ebben már a számítógép-programozók illetékesek.
Irodalom [1] Hajnal ‐ Nemetz ‐ Pintér ‐ Urbán: Matematika IV. (B fakt), Tankönyvkiadó, 1982[2] Császár Ákos: Végtelen sorok, Egyetemi jegyzet, Tankönyvkiadó, 1977. [3] H. Ch. Reichel: Wahrscheinlichkeitsrechnung und Statistik, Verlag Hölder ‐ Pichler ‐ Tempsky, Wien, 1989 [4] Rényi Alfréd: Valószínűségszámítás, Tankönyvkiadó, 1968 [5] Nemetz Tibor: Valószínűségszámítás, Tankönyvkiadó. 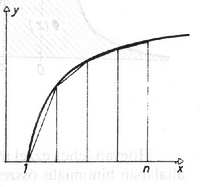 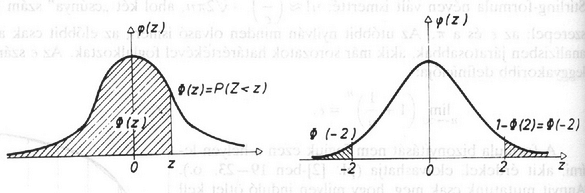 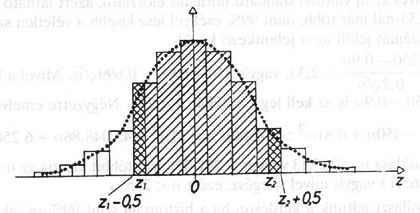 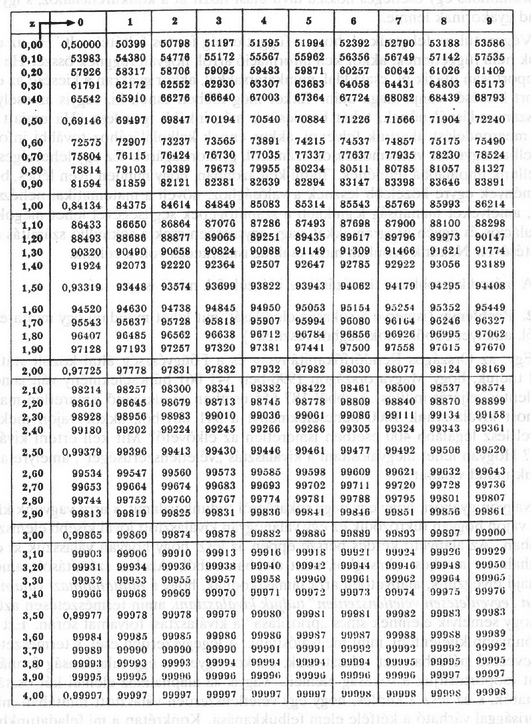 |